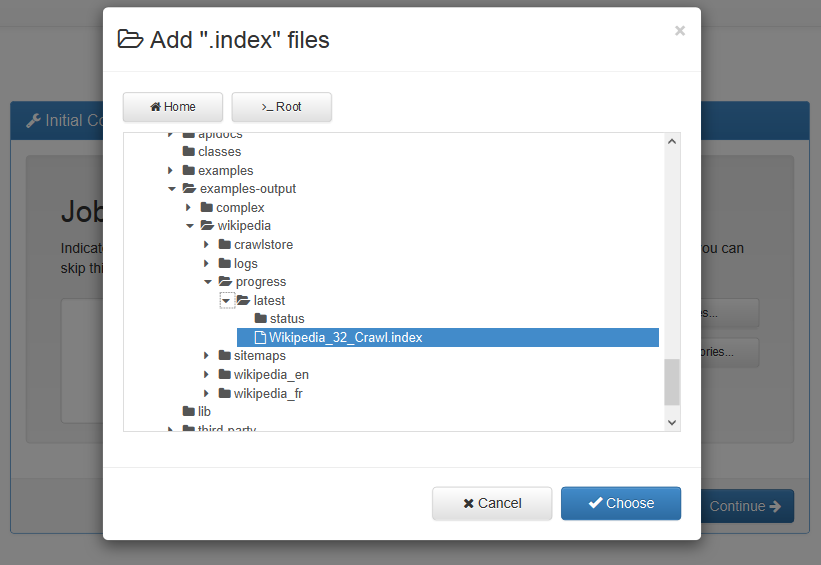
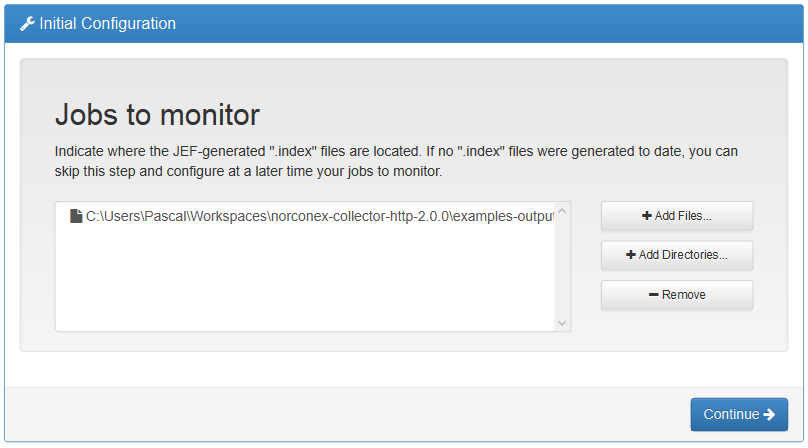
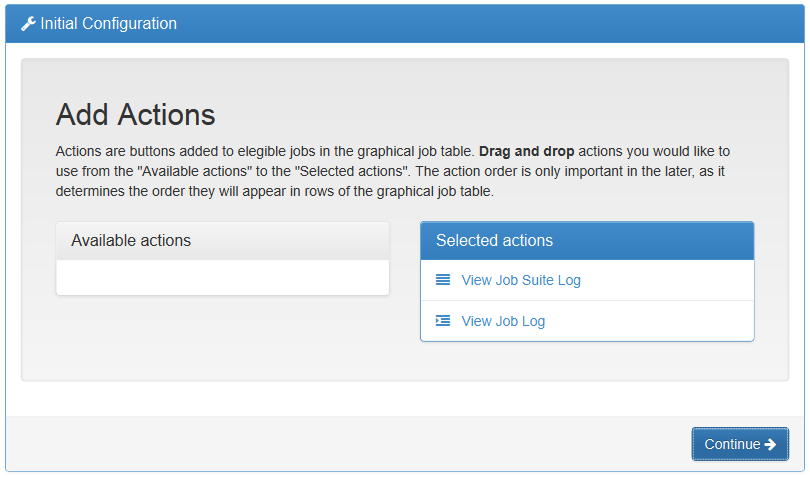
This release of Norconex Importer brings many fixes, increased stability, and nice new features. The following highlights some of the additions with XML configuration or Java code samples.
Retrieve a document Length
[ezcol_1half]
Thanks to the new DocumentLengthTagger, you can now store a document byte length in a metadata field of your choice. The length can be obtained at any document processing stage. For instance, it can be obtained before any transformation took place, or after it was parsed.
[/ezcol_1half]
[ezcol_1half_end]
<tagger class="com.norconex.importer.handler.tagger.impl.DocumentLengthTagger" field="doc-length" overwrite="true" > </tagger>
[/ezcol_1half_end]
Add the current date to a document
[ezcol_1half]
The new CurrentDateTagger allows to add the current date to a metadata field and date format of your choice. This can be useful to indicate when a document was actually processed by the Importer.
[/ezcol_1half]
[ezcol_1half_end]
<tagger class="com.norconex.importer.handler.tagger.impl.CurrentDateTagger" field="date-imported" format="yyyy-MM-dd" />
[/ezcol_1half_end]
Filter documents on numeric or date range
[ezcol_1half]
NumericMetadataFilter and DateMetadataFilter now allow you to filter documents based on metadata field numeric or date values, respectively. You can define both closed ranges and open-ended ranges.
[/ezcol_1half]
[ezcol_1half_end]
<!-- Numeric range filter --> <filter class="com.norconex.importer.handler.filter.impl.NumericMetadataFilter" onMatch="include" field="age" > <condition operator="ge" number="20" /> <condition operator="lt" number="30" /> </filter> <!-- Date range filter --> <filter class="com.norconex.importer.handler.filter.impl.DateMetadataFilter" onMatch="include" field="publish_date" > <condition operator="ge" date="TODAY-7" /> <condition operator="lt" date="TODAY" /> </filter>
[/ezcol_1half_end]
Use external parsers
[ezcol_1half]
Wrapping a Tika class of the same name, the new ExternalParser allows Java programmers to point to external command-line applications to parse documents. One example can be for using “pdftotext” to parse PDFs instead of the default PDF parser based on PDFBox, which is much slower (but does a better job overall).
[/ezcol_1half]
[ezcol_1half_end]
import java.util.Map;
import com.norconex.commons.lang.file.ContentType;
import com.norconex.importer.parser.GenericDocumentParserFactory;
import com.norconex.importer.parser.IDocumentParser;
import com.norconex.importer.parser.impl.ExternalParser;
public class CustomDocumentParserFactory extends GenericDocumentParserFactory {
@Override
protected Map<ContentType, IDocumentParser> createNamedParsers() {
Map<ContentType, IDocumentParser> parsers = super.createNamedParsers();
ExternalParser pdfParser = new ExternalParser();
pdfParser.setCommand(
// Replace this with your own executable path
"C:\\Apps\\pdftotext.exe",
"-enc", "UTF-8", "-raw", "-q", "-eol", "unix",
ExternalParser.INPUT_FILE_TOKEN,
ExternalParser.OUTPUT_FILE_TOKEN);
parsers.put(ContentType.PDF, pdfParser);
return parsers;
}
}
[/ezcol_1half_end]
Other improvements
There are more changes under the hood, like upgrading to Apache Tika 1.8, as well as the fixing of OutOfMemory errors and document parsing sometimes never returning. You can find the complete list of changes in the release notes.
Several of these improvements were made possible thanks to the great feedback of the open-source community. Keep doing so: you make a difference.
Useful links
- Download Norconex Importer 2.2.0.
- Find out how to get started.
- Report your issues and questions on Github.
- Use the Importer as part of one of Norconex Collectors (open-source crawlers).

 This tutorial will show you how to extend
This tutorial will show you how to extend