 During a recent client project, I was required to crawl several websites with specific requirements for each. For example, one of the websites required:
During a recent client project, I was required to crawl several websites with specific requirements for each. For example, one of the websites required:
- to have a meta tag content be used as a URL replacement for the actual URL,
- the header, footer and any repetitive content be excluded from each page,
- to be able to ignore robots.txt since it is meant for external crawlers only (Google, Bing, etc.), and
- to index them in LucidWorks.
LucidWorks built-in web crawler is based on Aperture. It is great for basic web crawls, but I needed more advanced features that it could not provide. I had to configure LucidWorks with an external crawler that had more advanced built-in capabilities and the ability to create new functionality.
Naturally, I turned to Apache Nutch. I was spending a fair amount of time cracking the code open, looking for plug-ins and so on, and at some point, Norconex HTTP Collector was introduced internally for testing before the official release. I decided to give it a go and see how well it would integrate with LucidWorks. I immediately found it easier to configure, with only one configuration file for my customization. The integration was actually smoother than I expected, thanks to the available Solr Commiter.
LucidWorks
Since LucidWorks uses Solr internally, the idea was simply to add the required constant fields and URL argument to the Solr Committer based on LucidWorks documentation on external crawlers integration and Nutch integration.
Here are the simple steps I took:
- Access LucidWorks admin console, and click on a collection (or create one in case you have not done so).
- Click on “Managed Data Sources”, choose a new data source of type “External” and fill the required information, similar to the following:
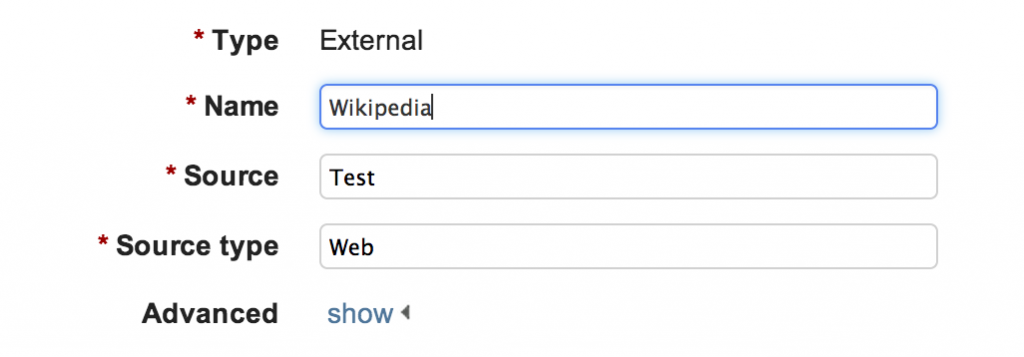
- In the URL field of your browser, you will find a number (e.g. 25 on older LucidWorks) or a code (e.g. 927df3075b544785892c6b4c51625714 in newer LucidWorks); please copy this somewhere as we need it later.
- Save the form and keep in mind that we will be using the values you provided in the next steps.
Norconex HTTP Collector
At a minimum, you will need the following required configurations to integrate your crawler with LucidWorks in the configuration file for your crawler:
<crawlers>
<crawler id="WikiCrawler">
<!-- Let's say we're crawling Wikipedia English in our example -->
<startURLs>
<url>http://en.wikipedia.org/</url>
</startURLs>
<importer>
<preParseHandlers>
<tagger class="com.norconex.importer.handler.tagger.impl.ConstantTagger">
<constant name="data_source">
927df3075b544785892c6b4c51625714
</constant>
<constant name="data_source_type">Web</constant>
<constant name="data_source_name">Wikipedia</constant>
</tagger>
</preParseHandlers>
</importer>
<committer class="com.norconex.committer.solr.SolrCommitter">
<solrURL>http://127.0.0.1:8888/solr/collection1/</solrURL>
<solrUpdateURLParams>
<param name="fm.ds">927df3075b544785892c6b4c51625714</param>
</solrUpdateURLParams>
<targetContentField>body</targetContentField>
<queueSize>25</queueSize>
<commitBatchSize>25</commitBatchSize>
</committer>
</crawler>
</crawlers>
In the above configuration snippet, you will notice that we are adding some constant fields for every document, and they are the same ones we added in LucidWorks when we created the external datasource:
- data_source: The code, or the number taken from the URL
- data_source_type: Web
- data_source_name: Wikipedia
In the Commiter configuration, we must add a parameter “fm.ds”, which LucidWorks expects when the documents are being indexed. This will allow you to use the “Edit Mapping” feature from the LucidWorks user interface for the content you are indexing.
Please note: With the newer LucidWorks, you must click on “Start Crawler” from the user interface before actually starting the Collector. Otherwise, LucidWorks may complain about having mapping issues with the datasource
Moving On…
With the Norconex HTTP Collector working just fine with LucidWorks, I easily configured the missing crawling features I was after. If you are using LucidWorks, I invite you to download and try Norconex HTTP Collector. If you need help or run into any issues, feel free to reach my colleagues or myself on GitHub or leave a comment below. I would also like to hear your experience with it.
Happy Crawling!
Khalid Alhomoud
Khalid is part of Norconex development team, sharing his expertise on both on professional services and products. His last few years have been busy developing Enterprise solutions using Java and Solr search engine. Khalid is also an Android developer, and previously worked as a server administrator before joining Norconex.