Introduction
In the era of data-driven decision-making, efficient data indexing is pivotal in empowering businesses to extract valuable insights from vast amounts of information. Elasticsearch, a powerful and scalable search and analytics service, has become popular for organizations seeking to implement robust search functionality. Norconex Web Crawler offers a seamless and effective solution for indexing web data to Elasticsearch.
In this blog post, you will learn how to utilize Norconex Web Crawler to index data to Elasticsearch and enhance your organization’s search capabilities.
Understanding Norconex Web Crawler
Norconex Web Crawler is an open-source web crawler designed to extract, parse, and index content from the web. The crawler’s flexibility and ease of use make it an excellent choice for extracting data from the web. Plus, Norconex offers a range of committers that index data to various repositories. See https://opensource.norconex.com/committers/ for a complete list of supported target repositories. If the provided committers do not meet your organizational requirements, you can extend the Committer Core and create a custom committer.
This blog post will focus on indexing data to Elasticsearch.
Prerequisites
Elasticsearch
To keep things simple, we will rely on Docker to stand up an Elasticsearch container locally. If you don’t have Docker installed, follow the installation instructions on their website. Once Docker is installed, open a command prompt and run the following command.
docker run -d -p 9200:9200 -p 9600:9600 -e "discovery.type=single-node" -e "xpack.security.enabled=false" elasticsearch:7.17.10This command does the following
- requests version 7.17.10 of Elasticsearch
- maps ports 9200 and 9600
- sets the discovery type to “single-node”
- disables the security plugin
- Starts the Elasticsearch container
Once the container is up, browse to http://localhost:9200 in your favourite browser. You will get a response that looks like this:
{
"name" : "c6ce36ceee17",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "gGbNNtDHTKCSJnYaycuWzQ",
"version" : {
"number" : "7.17.10",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "fecd68e3150eda0c307ab9a9d7557f5d5fd71349",
"build_date" : "2023-04-23T05:33:18.138275597Z",
"build_snapshot" : false,
"lucene_version" : "8.11.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}Elasticsearch container is now up and running!
Norconex Web Crawler
Download the latest version of the Web Crawler from Norconex’s website. At the time of this writing, version 3.0.2 is the most recent version.
Download the latest version of Elasticsearch Committer. At the time of this writing, version 5.0.0 is the most recent version.
Follow the automated installation instructions to install the Elasticsearch Committer libraries into the Crawler.
Crawler Configuration
We will use the following Crawler configuration for this test. Place this configuration in the root folder of your Crawler installation, with the filename my-config.xml.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE xml>
<httpcollector id="Norconex HTTP Collector">
<!-- Decide where to store generated files. -->
<workDir>./output</workDir>
<crawlers>
<crawler id="Norconex Elasticsearch Committer Demo">
<startURLs
stayOnDomain="true"
stayOnPort="true"
stayOnProtocol="true">
<url>https://github.com/</url>
</startURLs>
<!-- only crawl 1 page -->
<maxDepth>0</maxDepth>
<!-- We know we don't want to crawl the entire site, so ignore sitemap. -->
<sitemapResolver ignore="true" />
<!-- Be as nice as you can to sites you crawl. -->
<delay default="5 seconds" />
<importer>
<postParseHandlers>
<!-- only keep `description` and `title` fields -->
<handler class="KeepOnlyTagger">
<fieldMatcher method="csv">
description,title
</fieldMatcher>
</handler>
</postParseHandlers>
</importer>
<committers>
<!-- send documents to Elasticsearch -->
<committer class="ElasticsearchCommitter">
<nodes>http://localhost:9200</nodes>
<indexName>my-index</indexName>
</committer>
</committers>
</crawler>
</crawlers>
</httpcollector>Note that this is the minimal configuration required. There are many more parameters you can set to suit your needs. Norconex’s documentation does an excellent job of detailing all the parameters.
Start the Crawler
Norconex Web Crawler comes packaged with shell scripts to start the application. To start the crawler, run the following command in a shell terminal. The example below is for a Windows machine. If you are on Linux, use the collector-http.sh script instead.
C:\Norconex\norconex-collector-http-3.0.2>collector-http.bat start -clean -config=.\my-config.xmlRecall that you saved the Crawler configuration at the root of your Crawler installation.
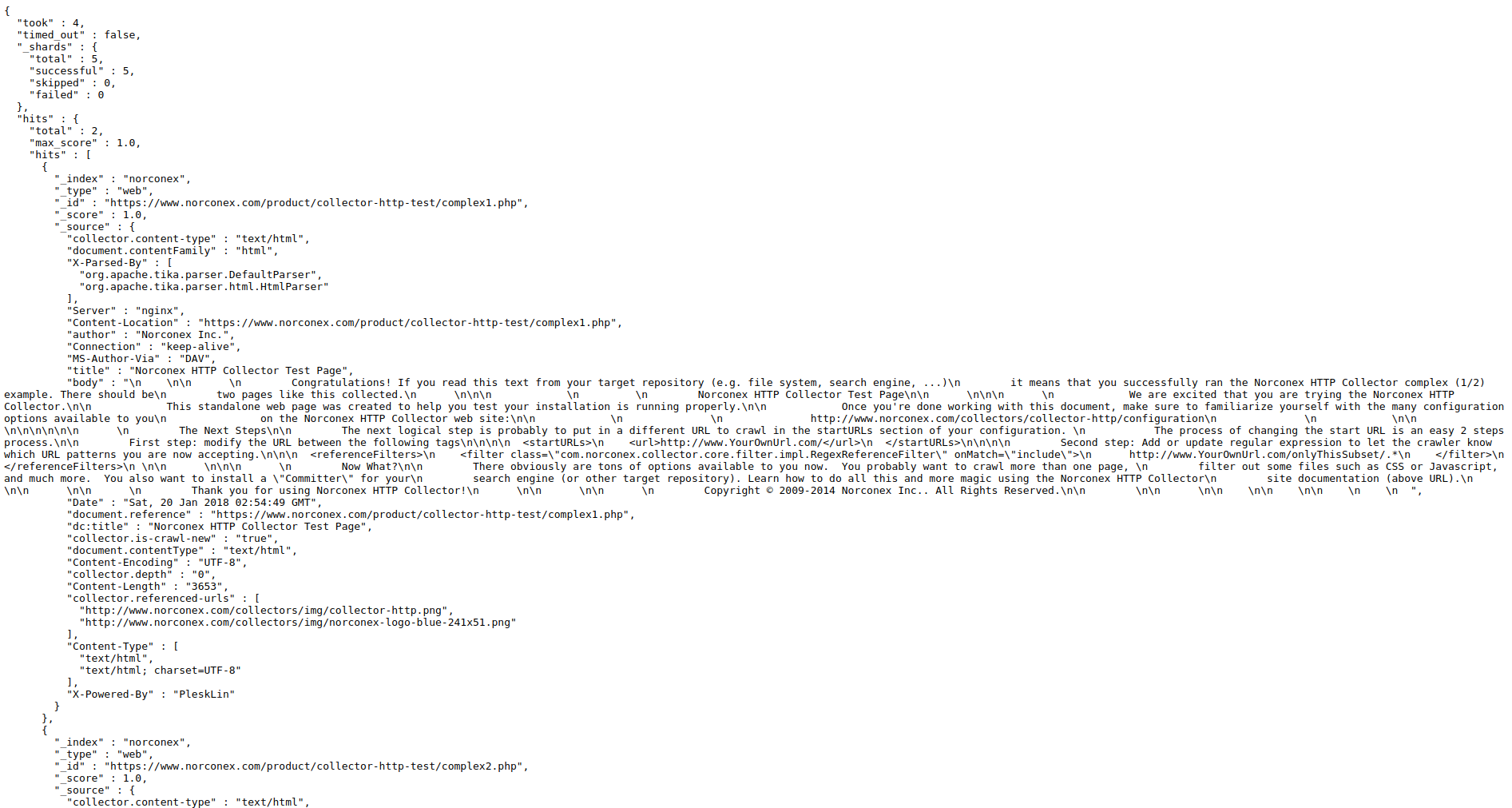
Since only a single page is being indexed, the crawl job will take only a few seconds. Once the job completes, query the Elasticsearch container by browsing to http://localhost:9200/my-index/_search in your browser. You will see something like this:
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "my-index",
"_id": "https://github.com/",
"_score": 1,
"_source": {
"title": "GitHub: Let's build from here · GitHub",
"description": "GitHub is where over 100 million developers shape the future of software, together. Contribute to the open source community, manage your Git repositories, review code like a pro, track bugs and features, power your CI/CD and DevOps workflows, and secure code before you commit it.",
"content": "<redacted for brevity>"
}
}
]
}
}You can see that the document was indeed indexed!
Conclusion
Norconex Web Crawler streamlines the process of indexing web data into Elasticsearch, making valuable information readily available for search and analytics.
This guide provides step-by-step instructions for integrating your data with Elasticsearch, unleashing potent search capabilities for your organization’s applications. Embrace the powerful synergy of Norconex Web Crawler and Elasticsearch to revolutionize your data indexing journey, empowering your business with real-time insights and effortless data discovery. Happy indexing!
 The next presenter, Michael Basnight, Software Engineer at Elastic, provided an Elastic Stack roadmap with demos of the latest and upcoming features. Kibana has added new capabilities to become much more than just the main user interface of Elastic Stack, with infrastructure and logs user interface. He introduced Fleet, which provides centralized config deployment, Beats monitoring, and upgrade management. Frozen indices allows for more index storage by having indices available and not taking up HEAP memory space until the indices are requested. Also, he provided highlights on Advanced Machine Learning analytics for outlier detection, supervised model training for regression and classification, and ingest prediction processor. Elasticsearch performance has increased by employing Weak AND (also called “WAND”), providing improvements as high as 3,700% to term search and improving other query types between 28% and 292%.
The next presenter, Michael Basnight, Software Engineer at Elastic, provided an Elastic Stack roadmap with demos of the latest and upcoming features. Kibana has added new capabilities to become much more than just the main user interface of Elastic Stack, with infrastructure and logs user interface. He introduced Fleet, which provides centralized config deployment, Beats monitoring, and upgrade management. Frozen indices allows for more index storage by having indices available and not taking up HEAP memory space until the indices are requested. Also, he provided highlights on Advanced Machine Learning analytics for outlier detection, supervised model training for regression and classification, and ingest prediction processor. Elasticsearch performance has increased by employing Weak AND (also called “WAND”), providing improvements as high as 3,700% to term search and improving other query types between 28% and 292%.





 The
The  The new
The new  The new
The new 

 You no longer have to hunt for a misconfiguration. Schema-based XML configuration validation was added and you will now get errors if you have a bad XML syntax for any configuration options. This validation can be trigged on command prompt with this new flag:
You no longer have to hunt for a misconfiguration. Schema-based XML configuration validation was added and you will now get errors if you have a bad XML syntax for any configuration options. This validation can be trigged on command prompt with this new flag:  Having to convert a duration in milliseconds is not the most friendly. Anywhere in your XML configuration where a duration is expected, you can now use a human-readable representation (English only) as an alternative.
Having to convert a duration in milliseconds is not the most friendly. Anywhere in your XML configuration where a duration is expected, you can now use a human-readable representation (English only) as an alternative. The new
The new 
 Norconex Committer and all is current concrete implementations (Solr, Elasticsearch, IDOL) have been upgraded and have seen a redesign of their web sites. Committers are libraries responsible for posting data to various repositories (typically search engines). They are in other products or projects, such as
Norconex Committer and all is current concrete implementations (Solr, Elasticsearch, IDOL) have been upgraded and have seen a redesign of their web sites. Committers are libraries responsible for posting data to various repositories (typically search engines). They are in other products or projects, such as