Introduction
In the ever-evolving landscape of enterprise search, maintaining optimal relevance in search results is a perpetual challenge. In fact, the delicate balance of relevance often teeters on the edge of uncertainty as organizations regularly update their data. An intricate web of parameters, filters, and algorithms dictates what users see in their search results, and those dynamics demand a strategic approach. The goal of that approach is to ensure updates do not inadvertently disrupt the delicate equilibrium of relevance. Accordingly, ensuring any changes made to alter search relevancy are moving the needle in the right direction is imperative.
Search relevance is a measure of how effectively a search system aligns with the user’s intentions and expectations. As the enterprise Search space has evolved, locating the correct documents has become easier, but arranging them in a meaningful sequence remains a formidable challenge.
The Problem
Many factors influence relevancy in an enterprise search solution. As data is added/removed or organizational search strategy changes, how can relevancy be measured to ensure it stays, well, relevant?
A Solution
In an ideal world, you would leverage users to identify “good” and “bad” search results and then tweak your search engine. However, this strategy may not be possible in the world of enterprise search due to budget or resource constraints. This raises a question: how can relevancy changes be tracked automatically? This blog presents one of many possible ways to track relevancy changes in an enterprise search solution. After the initial setup, this solution can largely be automated.
Step 1
Pick the top 100 (or 1,000 or more!) of the most popular terms of your search application. Ideally, these terms should be extracted from an analytics system already in place in the organization, such as Google Analytics.
Step 2
For each term in the list, figure out what a “good” set of results looks like. This task can be daunting, but it doesn’t need to be. As a starting point, take the current result set from your system for each term. Then, over time, this result set can be updated a few terms at a time. This list is your “ideal” result set — given a search term, this result set tells you information about which documents should be included and in what order.
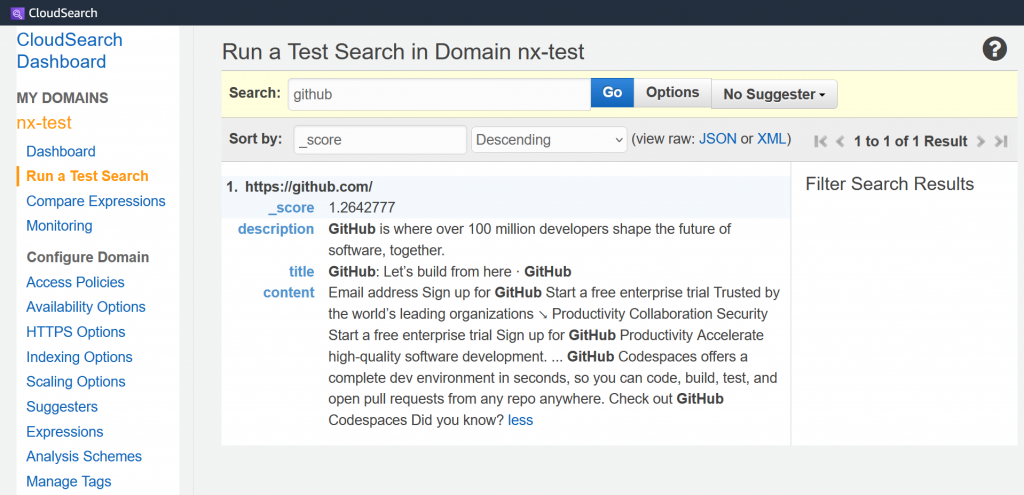
The list can be stored in a database or simply as a CSV. Here is an example of what a CSV might look like for a system where the top 5 results matter.
| homer simpson | id-123 | id-423 | id-391 | id-508 | id-185 |
| another thing user searches for | id-008 | id-872 | id-876 | id-281 | id-119 |
For the search term homer simpson, results must be in the following order: id-123, id-423, id-391, id-508, id-185.
Your organizational needs will ultimately determine which information is important. For example, if search strategy dictates that there is some flexibility with the order of search results, then the positions can be stored in the CSV. Here’s what that might look like.
| homer simpson | id-123 | 1-2 | id-391 | 2-4 | id-185 | 2-5 |
| another thing user searches for | id-008 | 1-1 | id-876 | 2-3 | id-119 | 3-5 |
For the term homer simpson, document with ID id-123 must either be the first or second result.
As noted previously, this list will never be complete. It will evolve alongside organizational needs. With time, terms will added/removed and results for existing term(s) will be adjusted.
Step 3
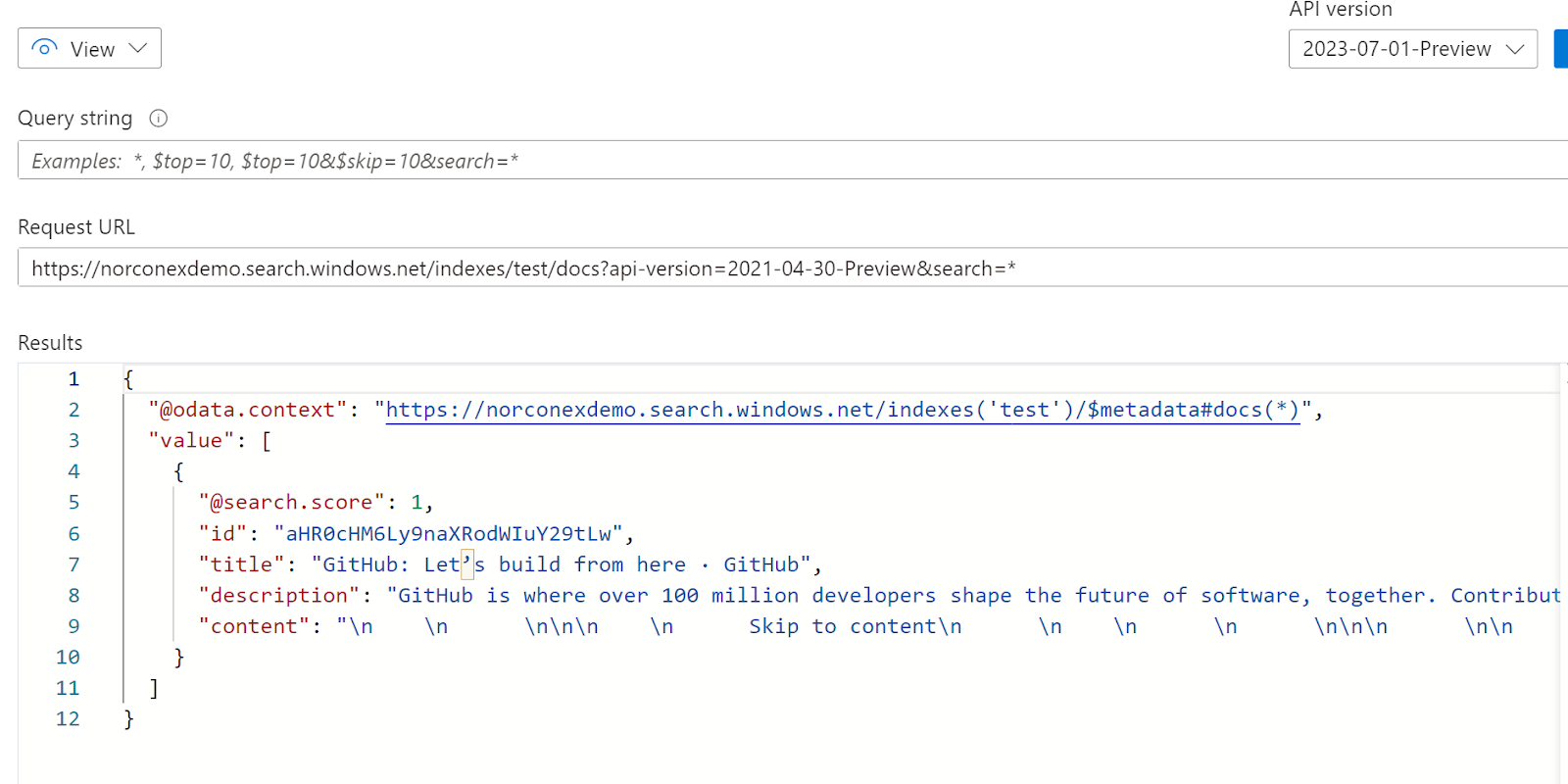
Build a tool in the language of your choice to compare the “ideal” list with the actual results from your search system.
This tool will need to do the following:
- Read the existing “ideal” list created in Step 2 above
- Query the search engine to record actual results from each term from the list
- Compare the actual vs ideal for each term
- Save the results in the target repo of your choice, which not only simplifies the evaluation process but also helps identify trends over time
For simplicity, having a formula for the comparison is beneficial. The end goal is to have a number that shows you whether a search term’s relevancy improved or worsened. In a solution with a flexible order of results, here’s what that formula might look like:
For each search result within a search term,
- if it is within the “ideal” range, give it a score of 0
- if it is higher or lower than it should be, find the difference in position
Add scores for each result. The closer this number is to 0, the closer the results are to the “ideal” result.
The tool is now built. Next, let’s look at how to use it.
Put It All Together
Every time the tool is run, you get a snapshot of how well the system is performing in terms of relevancy. Organizational goals, however, will ultimately dictate how often the tool is run. Perhaps more importantly, the tool enables you to test impacts to relevancy when making changes!
Let’s look at a factitious example.
Organizational search strategy now dictates that fieldA is the most important field in the data corpus. Accordingly, a boost rule is to be added that increases the weight of fieldA. Thanks to the tool, you can now understand how such a change will impact search relevancy.
- Run the tool to get current relevancy in the system
- Add the boost rule to the search application
- Run the tool again
- Compare results from Step 1 and 3
There you have it! With that practical solution, you can track relevancy changes in an enterprise search application.
Conclusion
The need for a strategic approach to track and adapt to changes is evident in the dynamic realm of enterprise search, where relevance is a perpetual challenge. But it doesn’t have to be one; the presented solution allows for adaptability to organizational changes, accommodating shifts in user expectations and content updates. While the initial setup may require thoughtful consideration of what constitutes an “ideal” result set, the subsequent automation of the process ensures ongoing relevancy assessment without overwhelming resource demands.
As organizations evolve, so too can their approach to tracking and adapting search relevancy. That evolution will help ensure a seamless alignment with user intentions and expectations in an ever-changing landscape.