Despite all the “noise” on social media sites, we can’t deny how valuable information found on social media networks can be for some organizations. Somewhat less obvious is how to harvest that information for your own use. You can find many posts online asking about the best ways to crawl this or that social media service: Shall I write a custom web scraper? Should I purchase a product to do so?
This article will show you how to crawl Facebook posts using the java-based, open-source crawler, Norconex HTTP Collector. The same approach can be applied to the Collector to crawl other social media sites such as Twitter or Google+. This article also serves as a tutorial on extending the Norconex HTTP Collector. At the bottom of this article, you can download the complete and fully-functional files used to create the examples below.
Web Site vs API
When thinking about a web crawler, the first thing that comes to mind is crawling websites – that is, extracting all HTML pages from a site along with URLs to other pages that will also be extracted as well as other referenced multimedia files (images, video, PDF, etc.). While this process is definitely a common usage, alternative crawling approaches are often more appropriate. For instance, whenever dealing with websites exposing structured or normalised “records” in HTML webpages, you will usually benefit from being able to obtain that data in a raw format instead. Crawling regular HTML web pages holding this information will generate a lot of noise you do not want (data labels, header, footer, side navigation, etc.). A typical solution to this problem is to extract the raw information from the page, stripping all markup and labels you do not want and using patterns in the page source you can identify. This is a flaky solution and should be avoided if possible. You do not want a simple UI change to break your crawler parsing logic. Luckily, many popular data-oriented websites offer HTTP APIs to access their content, free of any UI clutter. Such is the case with the free Facebook Graph API.
Facebook Graph API
Facebook offers a secure HTTP-based API. It allows developers to query public posts of specific users or organizations via authenticated HTTP calls.
To get started, you need a personal Facebook account. With that account, access the Facebook Developers website. From that site you will find, in the Tool & Support menu at the top, a very useful application called, “Graph API Explorer”. Using this application is a great way to familiarize yourself with the Facebook Graph API before moving further. Extensive Graph API documentation is also available on this site.

It is important to note that as of this writing, Facebook Graph API will simply not work with Facebook business accounts. You can use the API for your business, but you’ll have to create a personal account for this purpose.
Norconex HTTP Collector
If you do not already have a copy, download the Norconex HTTP Collector. If you are a first-time user, you can familiarize yourself with the Collector by first running the sample crawler configurations as described on the product’s Getting Started page.
In order to factor in logic specific to Facebook Graph API, we will cover appropriate configuration settings as well as provide custom implementations of certain crawler features. Java classes you write must end up in the “classes” folder of the Norconex HTTP Collector to be automatically picked up. You can find more information on extending the HTTP Collector here. You can always refer to the HTTP Collector Configuration page for additional information on what we’ll cover here.
Start URL
Let’s first establish what we want to crawl. For the purpose of this exercise, we will crawl Disney Facebook posts. Since we are using the Facebook Graph API, the URL obviously must be a valid Graph API URL. Obtaining this URL is fairly easy once you’ve familiarized yourself with the Graph API Explorer mentioned earlier. The URL can be found in the red rectangle in the image below. The reference to “disney” in the URL is the same reference you will see when accessing the Disney Facebook page on the web, ignoring character case: https://www.facebook.com/Disney.
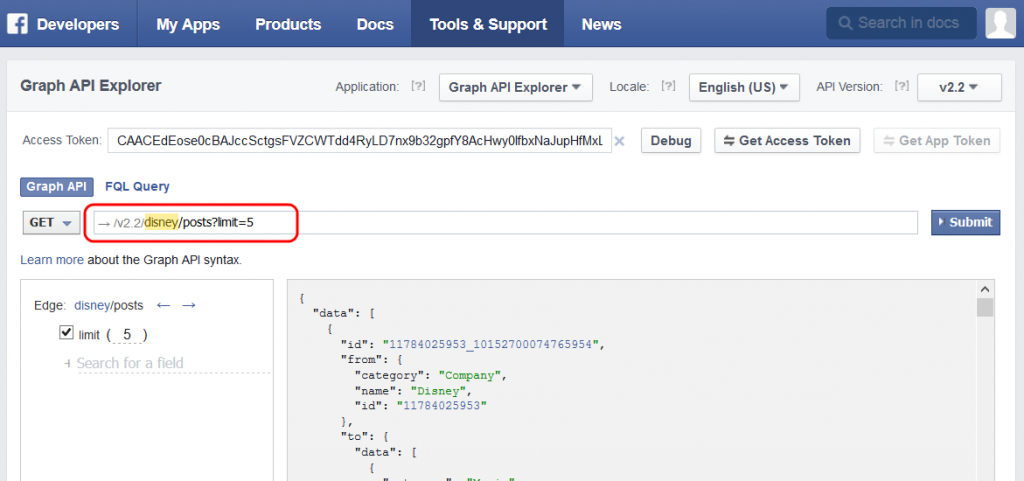
Let’s cut-and-paste that URL and make it the crawler “start URL” prefixed with the Graph API base URL:
<startURLs> <url>https://graph.facebook.com/v2.2/disney/posts?limit=5</url> </startURLs>
The above is the simplest URL we can create. In a “real-world” scenario, you probably want to get more than 5 posts at a time while also adding parameters to that URL such as explicitly listing fields to return (to limit your bandwidth usage and increase crawl performance).
Authentication
Using a plain URL like the one above won’t work without a little extra effort. Calls to the Facebook Graph API must be authenticated in which each Graph URL you invoke must contain a valid access token. See the above image, which contains an access token sample. Unfortunately, tokens eventually expire, so we can’t simply use the one from the Graph Explorer in our crawler. Because we do not want to manually provide a new token every time the crawler runs, a solution is to let the crawler fetch a new access token each time it runs before attempting to download any posts.
Luckily, the Facebook Graph API offers an easy way to get a fresh access token in exchange for a permanent “app id” and “app secret”. Facebook requires that you first create a Facebook application to obtain these. There are several tutorials online to help you with this step. Here is one from Facebook itself: https://developers.facebook.com/docs/opengraph/getting-started. You only need to perform the steps described in the “Create a Facebook App ID” section of the tutorial. Once you have obtained the app id and app secret, store them safely, and we’ll use them shortly.
Because the access token must be appended to every Graph API URL we invoke, we must modify the way the HTTP Collector invokes URLs – that’s the responsibility of the IHttpDocumentFetcher interface implementation. The default implementation is GenericDocumentFetcher, which already does a good job of downloading web content. We will reuse its existing logic by extending it, only to add the logic for appending the access token:
package com.norconex.blog.facebook.crawler;
public class FacebookDocumentFetcher extends GenericDocumentFetcher {
// This is the URL to use for dynamically obtaining a fresh access token
private static final String GRAPH_API_OAUTH_URL =
"https://graph.facebook.com/oauth/access_token?client_id=%s"
+ "&client_secret=%s&grant_type=client_credentials";
@Override
public CrawlState fetchDocument(
HttpClient httpClient, final HttpDocument doc) {
// Make sure we have a Facebook Graph API access token
ensureAccessToken(httpClient);
// Append the access token to the URL if it does not already exists
String originalReference = doc.getReference();
if (!originalReference.contains("&access_token=")) {
String oauthReference = appendAccessToken(originalReference);
doc.setReference(oauthReference);
}
// Let the parent class make the Facebook Graph API call
return super.fetchDocument(httpClient, doc);
}
private synchronized void ensureAccessToken(HttpClient httpClient) {
if (accessToken != null) {
return;
}
String url = String.format(GRAPH_API_OAUTH_URL, appId, appSecret);
LOG.debug("Extracting code using: " + url);
String response = URLStreamer.streamToString(url);
LOG.debug("Response: " + response);
if (response.startsWith("access_token")) {
String token = StringUtils.substringAfter(response, "=");
try {
accessToken = URLEncoder.encode(token, CharEncoding.UTF_8);
} catch (UnsupportedEncodingException e) {
throw new CollectorException(e);
}
} else {
throw new CollectorException(
"Could not obtain access token. Response was: " + response);
}
}
@Override
public void loadFromXML(Reader in) {
XMLConfiguration xml = ConfigurationUtil.newXMLConfiguration(in);
setAppId(xml.getString("appId"));
setAppSecret(xml.getString("appSecret"));
}
//code missing: download source file for entire code
}
You will notice an implantation of the loadFromXML method was provided so that the app id and app secret can be specified in your configuration file as follows:
<documentFetcher class="com.norconex.blog.facebook.crawler.FacebookDocumentFetcher"> <appId>YOUR_APP_ID</appId> <appSecret>YOUR_APP_SECRET</appSecret> </documentFetcher>
Extracting links to follow
The URL sample we used only returns 5 posts. To retrieve more, you can simply increase the limit. To retrieve much more, you will face a Graph API limit that will force you to use the Graph API “paging” feature. Paging URLs are already part of the JSON response containing a batch of posts.
{
"data": [
...
],
"paging": {
"previous": "https://graph.facebook.com/v2.2/11784025953/posts?limit=5&since=1422835323&__paging_token=enc_AewqNTBap5P9Mn4zVnvvfJd68CVUF9uTluiOIc4S7H10e-XRFHyZnYb6jBq0QfDl8-G7PHAoyENUMeufaNud2YRm",
"next": "https://graph.facebook.com/v2.2/11784025953/posts?limit=5&until=1422748808&__paging_token=enc_AezBUFp7OzFQT3n4obRprZcmCPhu1Cr9isb0JvDnTXrCvcy3uZAECw0ZltpHx_wxkd2e3uE8bgnSmRD_SLcy5ka7"
}
}
To extract just the URL, we do not need to parse the whole response. A simple regex can do the job, in which we implement the ILinkExtractor interface:
package com.norconex.blog.facebook.crawler;
public class FacebookLinkExtractor implements ILinkExtractor {
// This pattern catches the last pagination "next" element.
private static final Pattern NEXT_PATTERN = Pattern.compile(
"\"next\":\"([^\"]+?/posts\\?.*?)\"");
private static final int NEXT_PATTERN_GROUP_INDEX = 1;
@Override
public Set<Link> extractLinks(InputStream content, String reference,
ContentType contentType) throws IOException {
Set<Link> links = new HashSet<Link>();
// Extract "next" link from paging on Facebook JSON posts
// If more than one is present, the last one will be picked
Scanner scanner = new Scanner(content);
String nextURL = null;
while (scanner.findInLine(NEXT_PATTERN) != null) {
nextURL = scanner.match().group(NEXT_PATTERN_GROUP_INDEX);
}
scanner.close();
if (StringUtils.isNotBlank(nextURL)) {
nextURL = StringEscapeUtils.unescapeEcmaScript(nextURL);
nextURL = nextURL.replace("|", "%7C");
Link link = new Link(nextURL);
links.add(link);
}
// Optionally change/add to the logic to get other URLs from individual
// posts, such as those in the "link" JSON elements, or the /comments
// URLs, etc.
return links;
}
@Override
public boolean accepts(String reference, ContentType contentType) {
// Only extract URLs from Facebook JSON posts
return FacebookUtils.isPosts(reference);
}
//code missing: download source file for entire code
}
Extracted links will be followed just as regular href links are followed by crawlers in HTML pages. This code can be modified to extract additional types of URLs found in the JSON response such as image URLs or the URL of a page described by the post. In your configuration, it will look like this:
<linkExtractors> <extractor class="com.norconex.blog.facebook.crawler.FacebookLinkExtractor" /> </linkExtractors>
Breaking posts into individual documents
Based on the “limit” you provide in your Graph API URL, you will often end up with many posts in a single JSON response. Chances are you want to treat these posts as individual documents in your own solution. The HTTP Collector has the capability to split documents into smaller ones, which is achieved by an IDocumentSplitter interface implementation from the Importer module. Instead of implementing one directly, we will extend the AbstractDocumentSplitter abstract class.
package com.norconex.blog.facebook.crawler;
public class FacebookDocumentSplitter extends AbstractDocumentSplitter {
protected List<ImporterDocument> splitApplicableDocument(
SplittableDocument parentDoc, OutputStream output,
CachedStreamFactory streamFactory, boolean parsed)
throws ImporterHandlerException {
// First, we make sure only Facebook posts are split here but returning
// null on non-post references.
if (!FacebookUtils.isPosts(parentDoc.getReference())) {
return null;
}
List<ImporterDocument> postDocs = new ArrayList<>();
ImporterMetadata parentMeta = parentDoc.getMetadata();
JsonReader jsonReader = new JsonReader(parentDoc.getReader());
jsonReader.setLenient(true);
JsonObject json = null;
try {
json = (JsonObject) new JsonParser().parse(jsonReader);
} catch (ClassCastException e) {
throw new ImporterHandlerException("Cannot parse JSON input.", e);
}
// Each top-level "data" element is a single document/post.
JsonArray postsData = json.get("data").getAsJsonArray();
Iterator<JsonElement> it = postsData.iterator();
while (it.hasNext()) {
JsonObject postData = (JsonObject) it.next();
try {
ImporterDocument doc = createImportDocument(
postData, parentDoc.getReference(), parentMeta,
streamFactory);
if (doc != null) {
postDocs.add(doc);
}
} catch (IOException e) {
throw new ImporterHandlerException(e);
}
}
return postDocs;
}
protected ImporterDocument createImportDocument(
JsonObject json, String parentRef, ImporterMetadata parentMeta,
CachedStreamFactory streamFactory) throws IOException {
if (json == null) {
return null;
}
// METADADA
ImporterMetadata childMeta = new ImporterMetadata();
// Parse and assign any values you need for a child
String id = getString(json, "id");
childMeta.setString("id", id);
childMeta.setString("description", getString(json, "description"));
childMeta.setString("link", getString(json, "link"));
childMeta.setString("picture", getString(json, "picture"));
childMeta.setString("type", getString(json, "type"));
childMeta.setString("created_time", getString(json, "created_time"));
// Etc.
// Consider "message" as the document "content".
String content = getString(json, "message");
// Create a unique reference for this child element. Let's make it
// the URL to access this post in a browser.
// e.g. https://www.facebook.com/Disney/posts/10152684762485954
String ref = "https://www.facebook.com/" + fromName + "/posts/"
+ StringUtils.substringAfter(id, "_");
childMeta.setString(ImporterMetadata.DOC_REFERENCE, ref);
// We gathered enough data for a single doc, return it
return new ImporterDocument(
ref, streamFactory.newInputStream(content), childMeta);
}
//code missing: download source file for entire code
}
In our implementation, we use a JSON parser to hand-pick each field we want to keep in each of our “child” documents. We reference our implementation in the importer section of the configuration:
<importer>
<preParseHandlers>
<splitter class="com.norconex.blog.facebook.crawler.FacebookDocumentSplitter" />
</preParseHandlers>
</importer>
Wrap it up
Now that we have the Facebook-specific items “ironed out,” have a look at the many other configuration options offered by the Norconex HTTP Collector and the Norconex Importer module. You may find it interesting to add your own metadata to the mix, perform language detection, or otherwise. In addition, you may want to provide a custom location to store crawled Facebook posts. The sample configuration file has its <committer> section configured to use the FileSystemCommitter. You can create your own Committer implementation instead or use one of the existing committers available for free download (Solr, Elasticsearch, HP IDOL, GSA, etc.).
Ready, set, go!
Whether you reproduced the above examples or are using the sample files available for download below, you should now be in a position to try the crawler. Run it as usual, and monitor the logs for potential issues (Norconex JEF Monitor can also help you with the monitoring process).
If you use a similar approach with the Norconex HTTP Collector to crawl other social media sites, please share your comments below as we would like to hear about it!
Source files
Download the source file used to create this article:
![]() HTTP Collector 2.0 compatible (2015-02-04)
HTTP Collector 2.0 compatible (2015-02-04)
![]() HTTP Collector 2.3 compatible (2015-11-06)
HTTP Collector 2.3 compatible (2015-11-06)
![]() HTTP Collector 2.6 compatible (2017-03-30)
HTTP Collector 2.6 compatible (2017-03-30)
Pascal Essiembre
Pascal Essiembre has been a successful Enterprise Application Developer for several years before founding Norconex in 2007 and remaining its president to this day. Pascal has been responsible for several successful Norconex enterprise search projects across North America. Pascal is also heading the Product Division of Norconex and leading Norconex Open-Source initiatives.